
About Me
Soumyajit Gupta
Machine Learning - Neural Nets - Agentic AI - Computational Sciences
This is Soumo, based in Reno, Nevada. I'm a domain-driven neural network modeler and data scientist.
I graduated with a PhD - Computer Science in 2025 from the University of Texas at Austin. My thesis was on Multi-Task models for group-targeted Toxicity detection, co-advised by Matthew Lease and Maria De-Arteaga.
Presently I'm working as an AI Engineer and Modeler for Smart Dust Systems for over an year. I'm also open to explore Full-time In-person roles around applied AI and Agentic Modeling domain area.
Here's a link to my Thesis doc, till the Official one is out.

Real-World Results
Featured Projects
Explore my journey of shaping ideas into practical and scalable outcomes
- End-to-End cancer detection pipelines for biopsy tissue samples
- Low Rank, Fast and memory efficient Denoising Algorithms with error bounds
- Higher Order feature selection algorithms to weed out redundant and irrelevant features
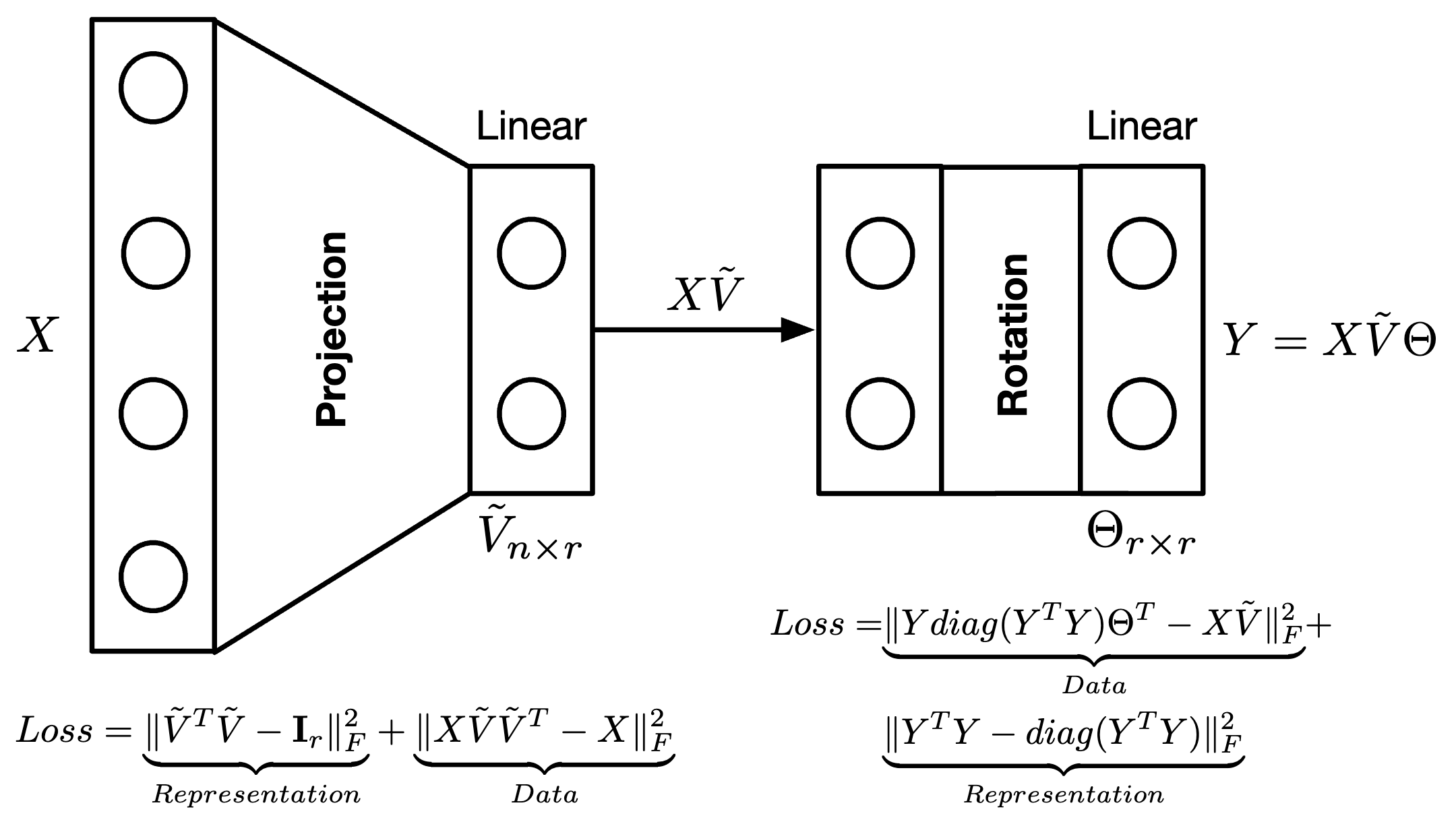
- Two stage neural engine as alternative to randomized SVD techniques
- Explicit Memory requirement: guided by feature dimension and desired rank
- Fully interpretable model: all outputs and weights have specific meaning
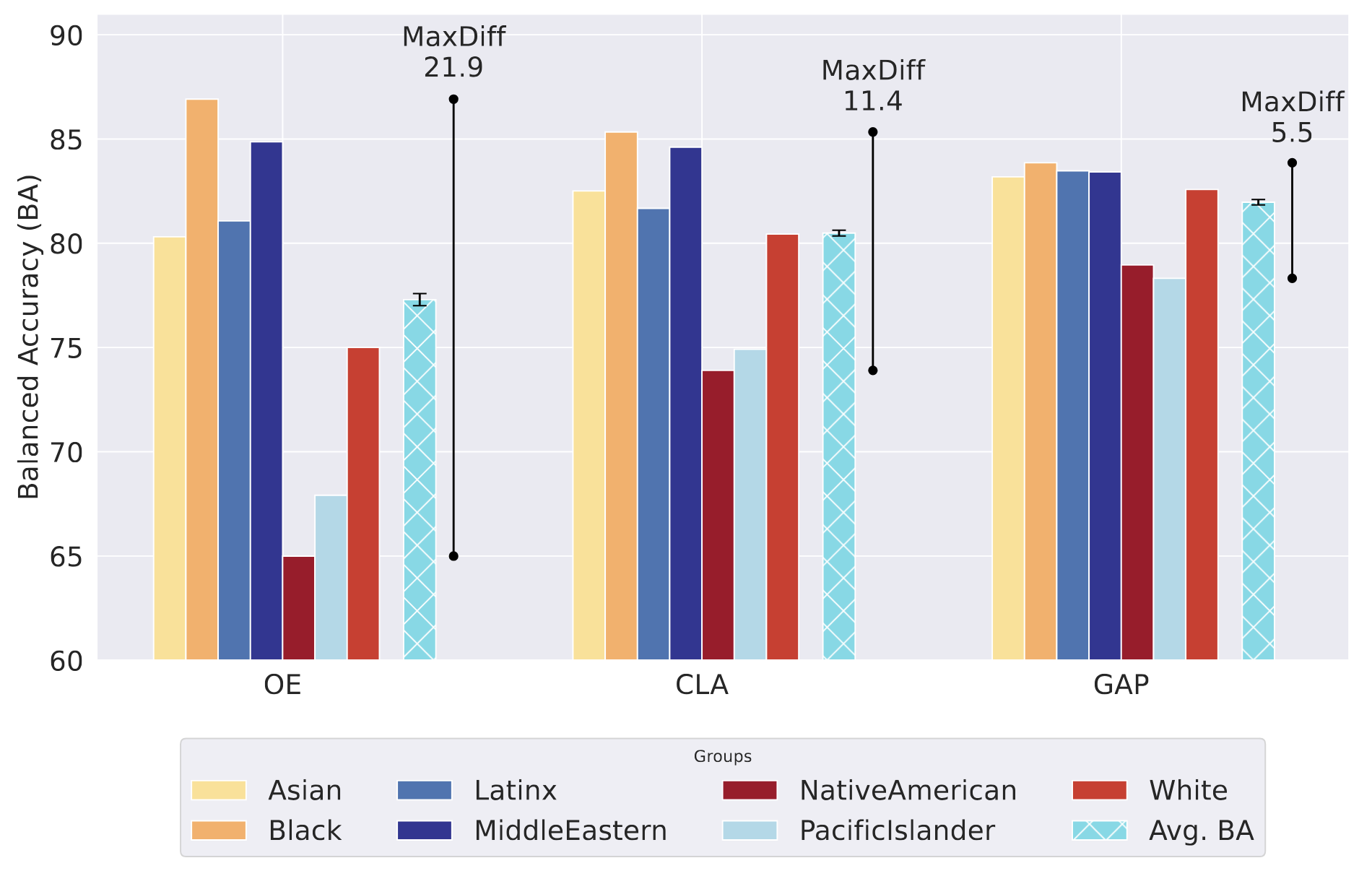
- Group-fairness loss function based on Accuracy Parity measure
- Balanced group accuracy around Target-group detection
- Group disparity reduced from ~22% to ~8% with minimal accuracy drop
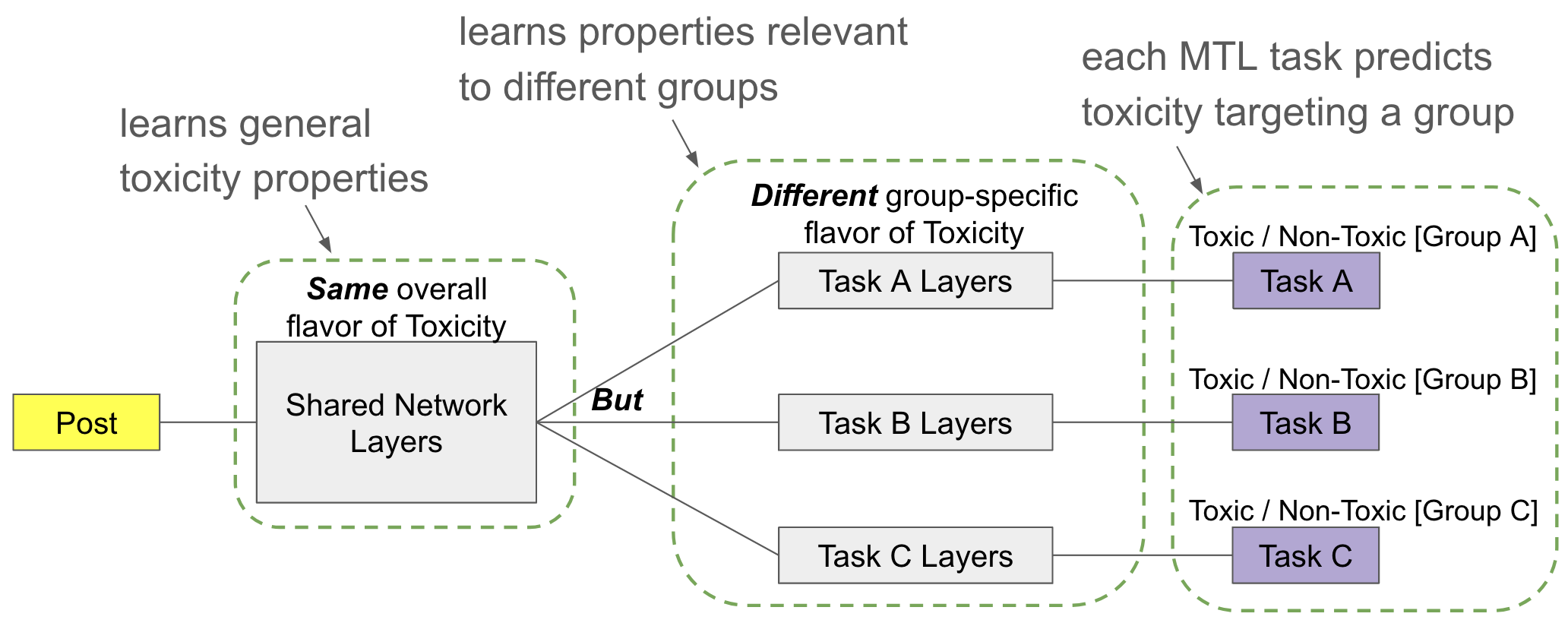
My Tools
Tech Skill Suite
Technologies that power my projects